책에 나온 Backup Diagram 을 이용하면 MDP 의 Value Function 즉, 기대값을 시각적으로 볼 수 있다.
MDP 에서 Value Function 의 확률과 확률 변수
앞서 얘기했듯이 기대값을 구하기 위해 확률과 확률 변수 값이 필요하다.
MDP 에서 Value Function ( 기대값) 을 구하기 위해 필요한 확률과 확률 변수는 다음과 같다.
| 확률 | |
|---|---|
| 상태 전이 확률 | |
| 상태(s)에서 행동(a)를 택할 확률 |
| 확률 변수 | |
|---|---|
| 정책을 수행하여 얻은 값 |
Backup Diagram of Value Function
위의 확률과 확률 변수를 조합하여 Value Function 을 Backup Diagram 을 표시 하면 아래 그림과 같다.
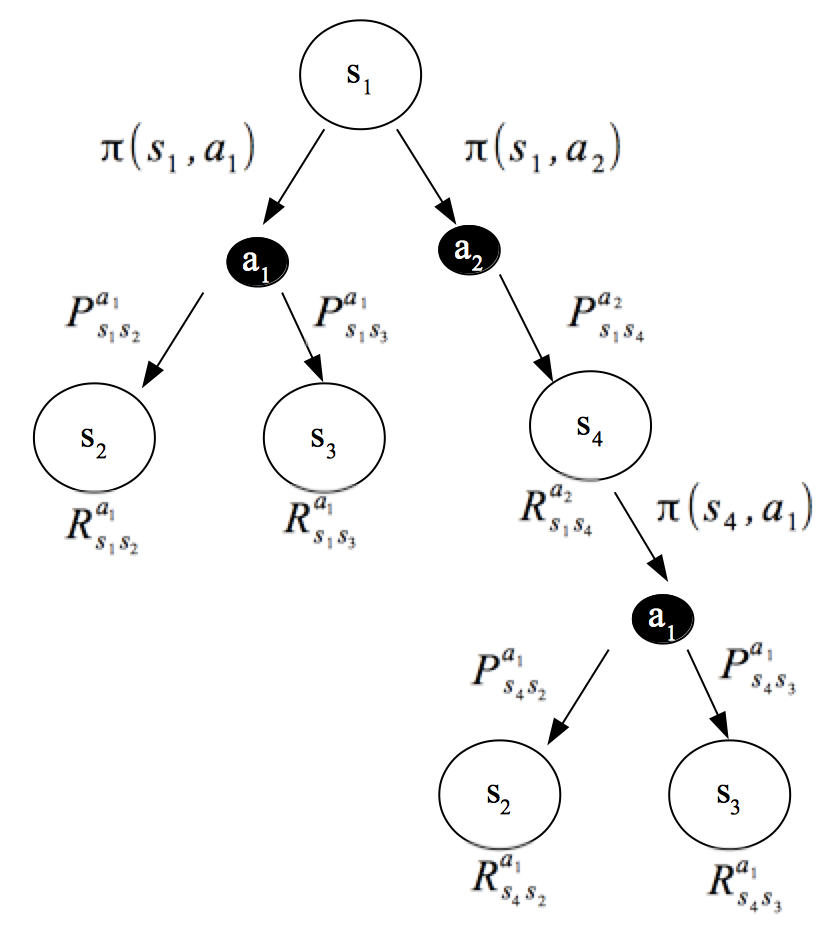
여기서 그림상으로 보면, 두 개의 확률 을 거쳐야 보상을 얻을 수 있는 것을 알 수 있다.
즉, MDP 에 하나의 보상(Reward)를 얻기 위해서는 두 개의 확률을 곱해야 한다.